
During this post we will discuss about the commonly used SYSTEM function used in Snowflake. Snowflake provides Control functions that allow you to execute actions in the system (e.g. aborting a query). Also some of the are Information functions that return information about the system (e.g. calculating the clustering depth of a table).
Please find below list of the SYSTEM functions which we generally use in our project on day-to-day basis.
DEPTH
- SYSTEM$CLUSTERING_DEPTH: provide an overview of how well a table is clustered and Computes the average depth of the table according to the clustered columns defined for the table. The average depth of a populated table (i.e. a table containing data) is always 1or more. The smaller the average depth, the better clustered the table is with regards to the specified columns.
select system$clustering_depth(‘INVOICE’,’INVC_NO’);

2. SYSTEM$CLUSTERING_INFORMATION :This system function provides more detail of clustering information than clustering_depth.
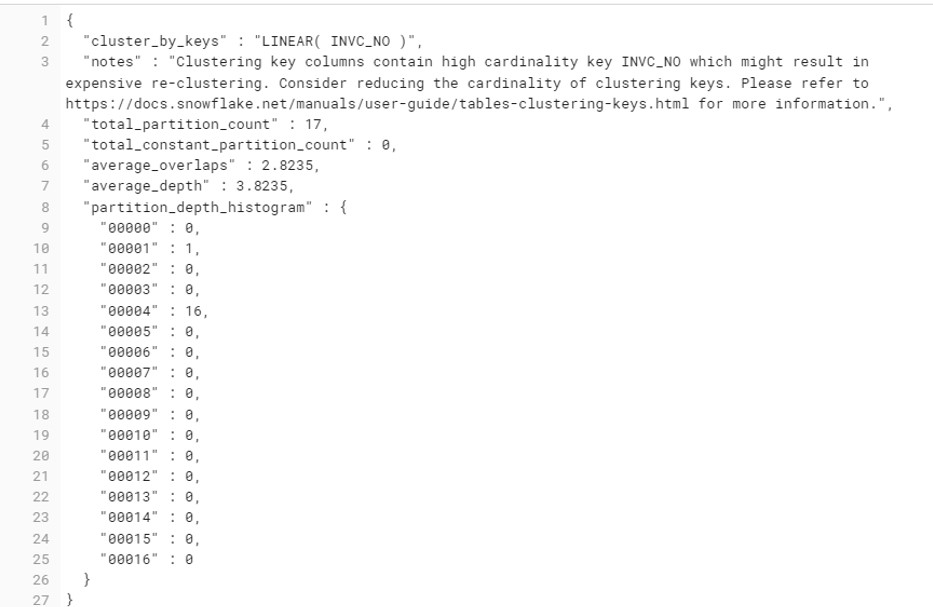
Key components of the histogram detail on clustering information.
total_partition_count :Total number of micro-partitions that comprise the table.
total_constant_partition_count:Total number of micro-partitions for which the value of the specified columns have reached a constant state
average_overlaps:Average number of overlapping micro-partitions for each micro-partition in the table. A high number indicates the table is not well-cluster.
partition_depth_histogram: its first number is depth level, 2nd number is the number of files in that depth level
The histogram contains buckets with widths:
- 0 to 16 with increments of 1.
- For buckets larger than 16, increments of twice the width of the previous bucket (e.g. 32, 64, 128, …
STATUS
3. SYSTEM$PIPE_STATUS(<<PIPE>>): Retrieve the current status of the pipe and the results are available in JSON format. Returns results only for the pipe owner (i.e. the role with the OWNERSHIP privilege on the pipe) or a role with the MONITOR privilege on the pipe.
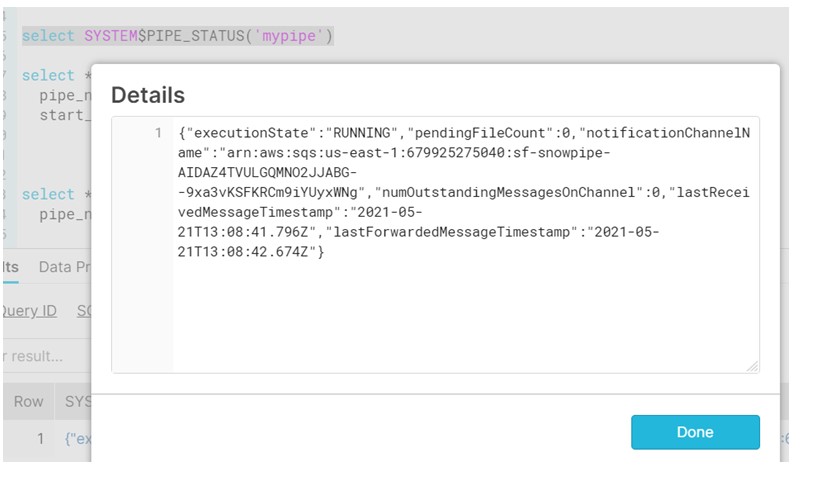
Execution state of the pipe; could be any one of the following:
RUNNING, STOPPED_CLONED, STOPPED_FEATURE_DISABLED, STOPPED_STAGE_DROPPED,STOPPED_FILE_FORMAT_DROPPED,STOPPED_MISSING_PIPE,STOPPED_MISSING_TABLE,STALLED_COMPILATION_ERROR,STALLED_INITIALIZATION_ERROR,STALLED_EXECUTION_ERROR,STALLED_INTERNAL_ERROR,PAUSED, PAUSED_BY_SNOWFLAKE_ADMIN, PAUSED_BY_ACCOUNT_ADMIN
pendingFileCount: Number of files currently being processed by the pipe. When this value is 0, either there are no files queued for this pipe or the pipe is effectively paused.
lastReceivedMessageTimestamp:
Specifies the timestamp of the last event message received from the message queue. If the timestamp is earlier than expected, this likely indicates an issue with either the service configuration.
lastForwardedMessageTimestamp: If event messages are getting received from the message queue but are not forwarded to the pipe, then there is likely a mismatch between the blob storage path where the new data files are created and the combined path specified in the Snowflake stage and pipe definitions
RETURN
4. SYSTEM$SET_RETURN_VALUE: Explicitly sets the return value for a task.
In a tree of tasks, a task can call this function to set a return value. Another task that identifies this task as the predecessor task (using the AFTER keyword in the task definition) can retrieve the return value set by the predecessor task.
Suppose you want to return some “defined value” from the Stored procedure to the TASK ,then we can call this function to set the value and later on use system$get_predecessor_return_value to consume or retrieve the value.
For example refer https://docs.snowflake.com/en/sql-reference/functions/system_set_return_value.html
5. SYSTEM$TASK_DEPENDENTS_ENABLE: Recursively resumes all dependent tasks tied to a specified root task. Once the task is created need to enable or put task in schedule. We need to do it manually for either Parent or Child task. Consider the scenario where you have one parent and have 50 child task then we need to resume all 50 tasks manually.
To recursively enable all dependent tasks tied to a root task, rather than enabling each task individually.
SELECT SYSTEM$TASK_DEPENDENTS_ENABLE(<<ROOT_TASK>>)
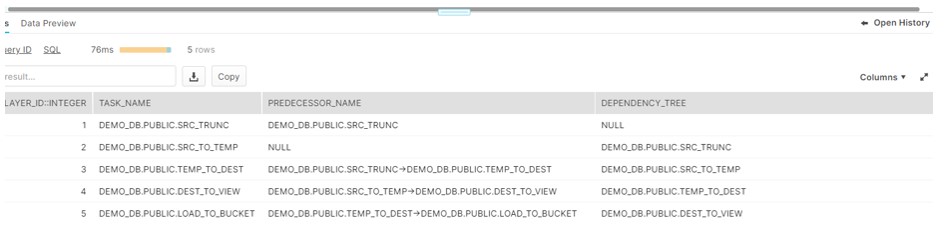
In above figure ,we need to enable only SRC_TRUCK Root task instead of enabling every task manually.
SELECT SYSTEM$TASK_DEPENDENTS_ENABLE(‘SRC_TRUNC’).
We will discuss some more SYSTEM function in next post. Please Click here to get details.












