Automating Snowflake External Table Creation: If you’ve worked with Snowflake External Tables, you’ve likely encountered this scenario: you have a source file with 100+ columns in S3, and you need to create an external table. The traditional approach requires manually parsing and defining each column—a tedious, error-prone process that can take time.
Snowflake gives us two powerful tools:
- INFER_SCHEMA – scans staged files and returns:
- USING TEMPLATE + GENERATE_COLUMN_DESCRIPTION – can auto-generate column definitions.
These work beautifully when you’re creating regular tables. While out of the box they don’t fully solve the “wide external table” problem, there’s a disconnect
The Challenge:
- For CSV external tables, using INFER_SCHEMA and USING TEMPLATE leads to an external table where only the VALUE column is populated and all derived columns are NULL.
- Or, if you change the file format, you get data in the columns – but the column names become C1, C2, C3 instead of meaningful names.
- For Parquet external tables, INFER_SCHEMA knows everything, but you still end up copy–pasting a huge column definition list unless you automate it yourself.
- With 100+ columns, this manual process is:
- Time-consuming (hours of copy-paste-edit)
- Error-prone (typos in column names or data types)
- Frustrating (repetitive work that should be automated)
The CSV Experiment: Two Attempts, Two Different Problems
The CSV Experiment: Two Attempts, Two Different Problems
CREATE OR REPLACE FILE FORMAT public.csv_format1
TYPE = CSV
PARSE_HEADER = TRUE
SKIP_BLANK_LINES = TRUE
TRIM_SPACE = TRUE
NULL_IF = ('NULL', 'null')
EMPTY_FIELD_AS_NULL = TRUE;
CREATE OR REPLACE FILE FORMAT public.csv_format
TYPE = CSV
SKIP_HEADER = 1 -- no PARSE_HEADER here
NULL_IF = ('NULL', 'null')
EMPTY_FIELD_AS_NULL = TRUE;
CREATE OR REPLACE STAGE public.external_csv_stage
URL = 's3://sharedbucket29/countrycode/'
STORAGE_INTEGRATION = s3_int
FILE_FORMAT = public.csv_format1;
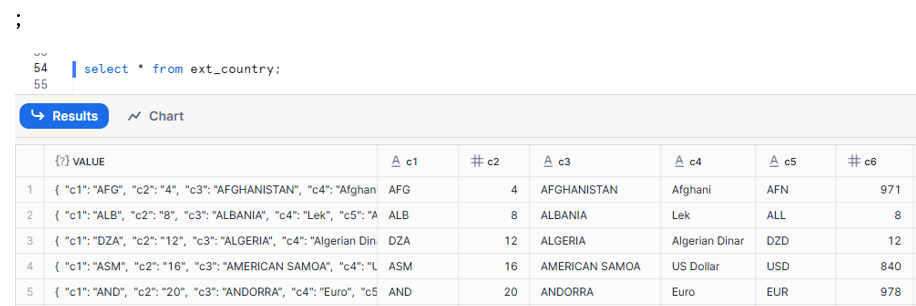
Attempt 1: Use header-aware format (csv_format1) in INFER_SCHEMA
CREATE OR REPLACE EXTERNAL TABLE ext_country_parse
USING TEMPLATE (
SELECT ARRAY_AGG(OBJECT_CONSTRUCT(*))
FROM TABLE
(
INFER_SCHEMA(
LOCATION=>'@public.external_csv_stage/',
FILE_FORMAT=>'csv_format1'
)
)
)
LOCATION=@public.external_csv_stage
FILE_FORMAT=csv_format;
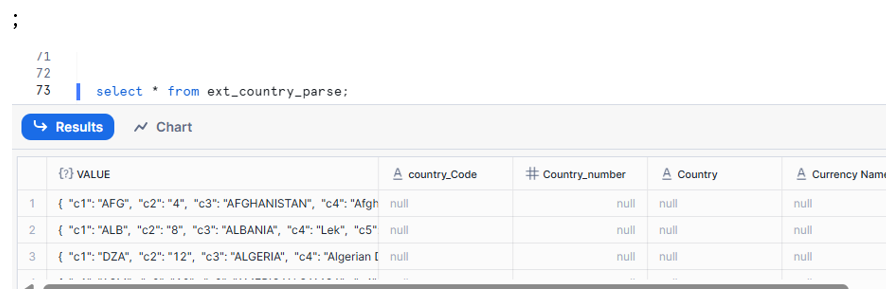
Attempt 2: Use non-header format (csv_format) for INFER_SCHEMA and external table
CREATE OR REPLACE EXTERNAL TABLE ext_country
USING TEMPLATE (
SELECT ARRAY_AGG(OBJECT_CONSTRUCT(*))
FROM TABLE
(
INFER_SCHEMA(
LOCATION=>'@public.external_csv_stage/',
FILE_FORMAT=>'csv_format'
)
)
)
LOCATION=@public.external_csv_stage
FILE_FORMAT=csv_format;
Result:
- External table is created.
- VALUE and all projected columns now contain data
- But the column names are generic (e.g., C1, C2, C3) instead of country_Code, Country_number, etc.
Solution : Let INFER_SCHEMA Generate Metadata, Then Build VALUE:cN Automatically
For CSV Files
CREATE OR REPLACE FILE FORMAT public.csv_infer_fmt
TYPE = CSV
PARSE_HEADER = TRUE
SKIP_BLANK_LINES = TRUE
TRIM_SPACE = TRUE
NULL_IF = ('NULL', 'null')
EMPTY_FIELD_AS_NULL = TRUE;
— File format for the actual external table (no header parsing)
CREATE OR REPLACE FILE FORMAT public.csv_ext_fmt
TYPE = CSV
SKIP_HEADER = 1
NULL_IF = ('NULL', 'null')
EMPTY_FIELD_AS_NULL = TRUE;
— External stage pointing to S3
CREATE OR REPLACE STAGE public.external_csv_stage
URL = 's3://sharedbucket29/countrycode/'
STORAGE_INTEGRATION = s3_int
FILE_FORMAT = public.csv_infer_fmt;
— File format for Parquet
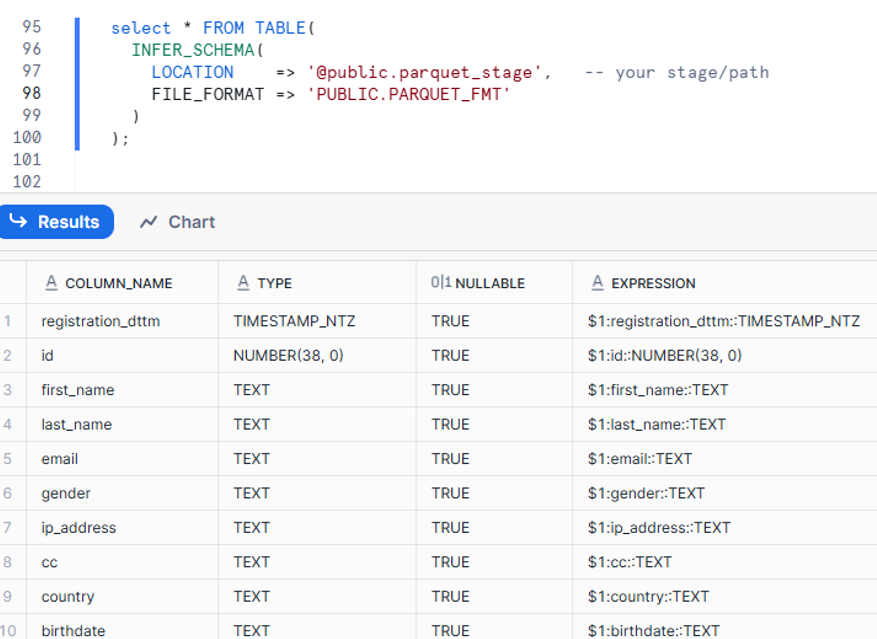
For Parquet Files
CREATE OR REPLACE FILE FORMAT public.parquet_fmt
TYPE = PARQUET;
— External stage for Parquet files
CREATE OR REPLACE STAGE public.parquet_stage
URL = 's3://srcbucketsachin/parquet_vector/'
STORAGE_INTEGRATION = s3_int
FILE_FORMAT = public.parquet_fmt;
Before automating, verify that INFER_SCHEMA() works correctly:
For CSV Files:
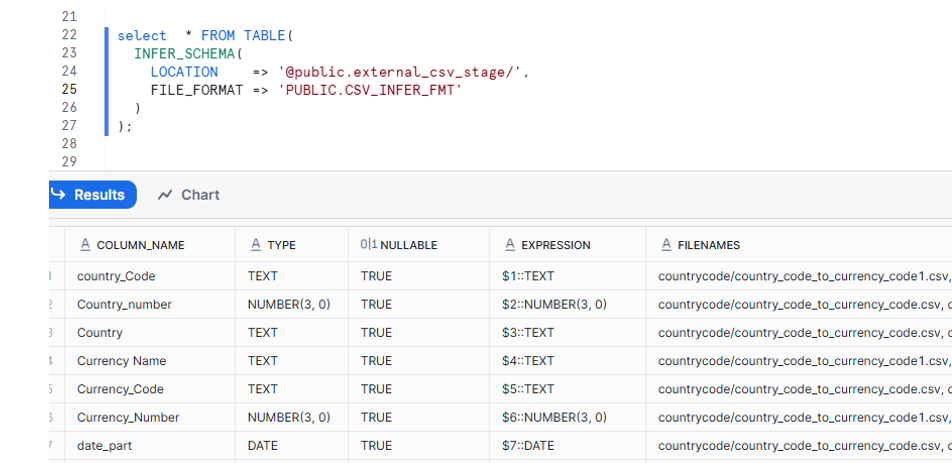
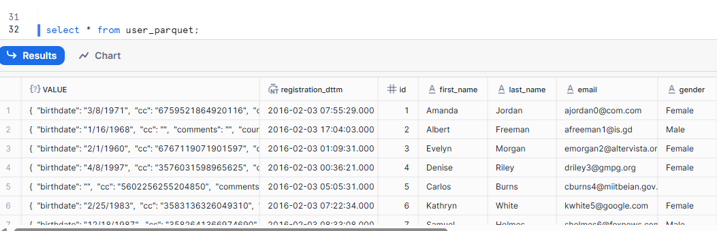
For Parquet Files:
Automated External Table Creation: CSV:

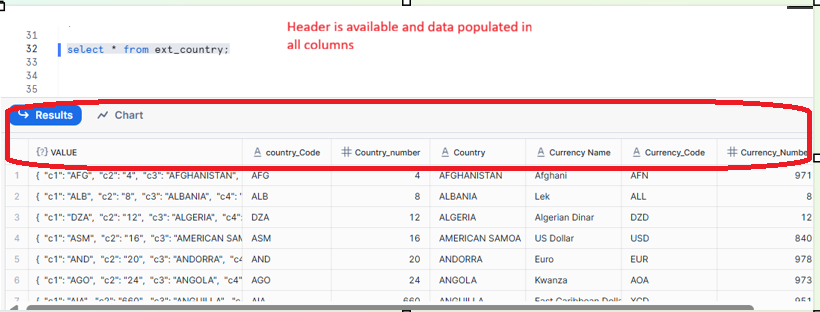
Automated External Table Creation: Parquet:
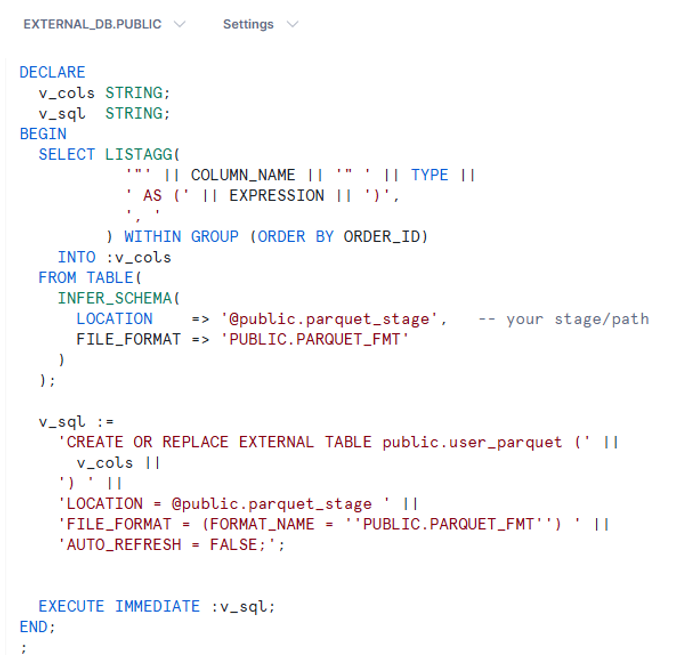
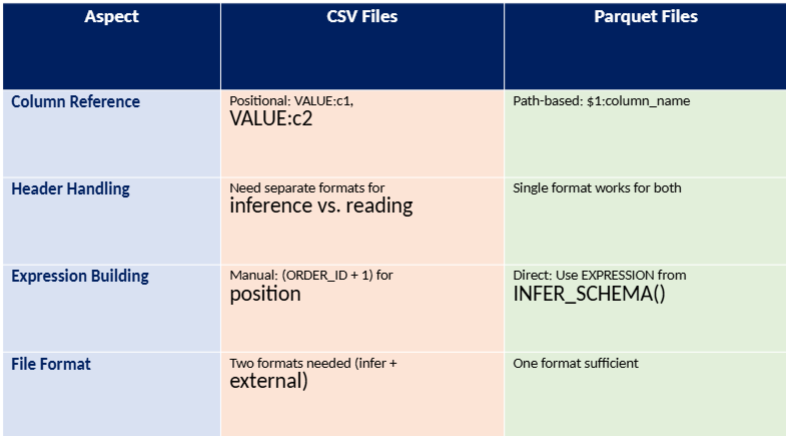
Key Differences: CSV vs. Parquet:
While Snowflake’s INFER_SCHEMA() is powerful, bridging the gap to External Table creation required custom logic. This solution eliminates the manual drudgery of defining 100+ columns and makes External Table creation as simple as running a procedure.