Parallel Snowflake Jobs with Snowpark: The Challenge: Sequential Bottlenecks
Imagine you’re loading sales data from multiple regions into Snowflake. Your pipeline needs to:
- Load North American sales data (2 minutes)
- Load European sales data (2 minutes)
- Load Asian sales data (2 minutes)
- Update high-value customer segments (1 minute)
- Update medium-value customer segments (1 minute)
- Update low-value customer segments (1 minute)
Traditional sequential execution would take 9 minutes. But here’s the catch: these operations are completely independent. They don’t depend on each other’s results. Why should we wait?
The Solution: Asynchronous Parallel Execution
Snowflake’s Snowpark API provides powerful async capabilities that let you run multiple independent queries simultaneously. With async execution, those same operations can complete in approximately 2 minutes – the time of your longest-running query.
Understanding the Async Pattern
The Core Components
collect() vs collect_nowait() vs create_async_job()
- collect()
Submits the statement and waits for it to finish; if it’s a SELECT, it also fetches the result rows into the client. - collect_nowait()
Submits the statement to Snowflake without waiting. It returns quickly with an object that contains a query_id.
Think “fire-and-forget (for now)”. - session.create_async_job(query_id)
This does not start a new query. It creates a client-side handle for an already-running query (identified by query_id).
You use this handle to:- is_done() → check completion
- job.result() → fetch the outcome (rows for SELECT)
- job.cancel() → Stops the query if needed
Real-World Implementation
Real-World Implementation
Sample table:
CREATE OR REPLACE TRANSIENT TABLE DEMO_DB.PUBLIC.CUSTOMER_DATA (
CUSTOMER_ID INT,
SEGMENT VARCHAR(50),
LOYALTY_SCORE INT,
PURCHASE_TRENDS VARCHAR(100),
UPDATED_TS TIMESTAMP
);
INSERT INTO DEMO_DB.PUBLIC.CUSTOMER_DATA
SELECT
SEQ4() AS CUSTOMER_ID,
CASE
WHEN MOD(SEQ4(), 3) = 0 THEN 'High Value'
WHEN MOD(SEQ4(), 3) = 1 THEN 'Medium Value'
ELSE 'Low Value'
END AS SEGMENT,
NULL AS LOYALTY_SCORE,
NULL AS PURCHASE_TRENDS,
CURRENT_TIMESTAMP AS UPDATED_TS
FROM TABLE(GENERATOR(ROWCOUNT => 100000));
Here’s a practical example that loads regional sales data and updates customer segments in parallel:



Let’s Break Down What We Just Built
Launching Jobs in Parallel
async_jobs = []
for region, query in region_queries.items():
print(f"Starting data load for {region}...")
print(query)
query_id = session.sql(query).collect_nowait().query_id
print(f"Submitted. Query ID = {query_id}")
async_job = session.create_async_job(query_id)
async_jobs.append((region, async_job))
What we did:
- Looped through all operations
- Started each query with collect_nowait() (non-blocking)
- query_id = the receipt number for that running query inside Snowflake.
- Created an async job handle for each
- Stored everything in a list for tracking
The Polling Loop
while any(not job.is_done() for _, job in async_jobs):
print(f"Waiting for {sum(not job.is_done() for _, job in async_jobs)} jobs to complete...")
- any(not job.is_done() …) → “Is any job still running?” If yes, keep waiting.
- sum(not job.is_done() …) → “How many are still running?” (nice progress print)
Collecting Results (what you really get)
if job.is_done():
result = job.result()
- is_done() confirms completion.
- result() gives the final outcome for that statement:
Execute the Procedure and get the output:
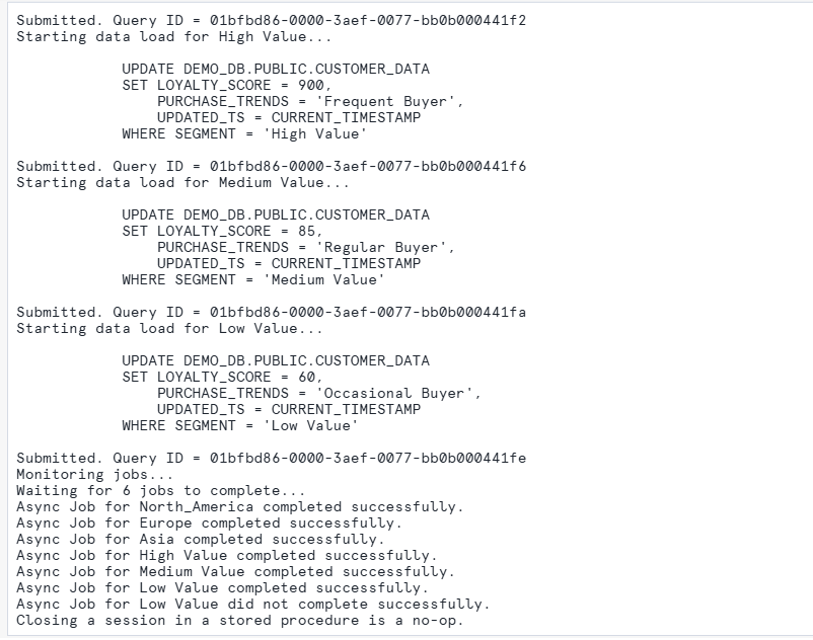
Verify the Query history:
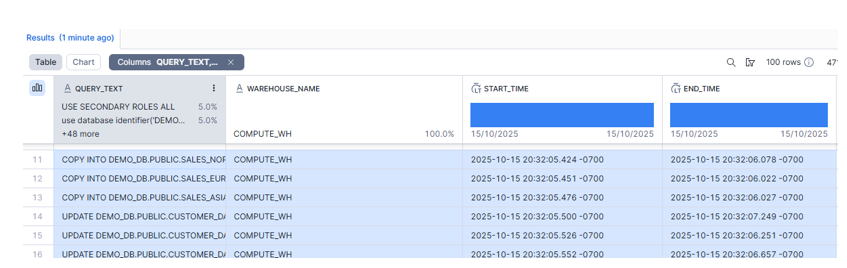
All 6 statements started within ~0.13 seconds of each other:
- First start: 20:32:05.424
- Last start: 20:32:05.552
That <200ms spread shows they were submitted together and ran in parallel. The batch completed when the longest one finished at 20:32:07.249.”
Key Benefits
Dramatic Performance Improvements
- Run independent operations simultaneously
- Reduce pipeline execution time and Maximize Snowflake compute utilization
- No idle time waiting for sequential operations
- Efficient use of Snowflake credits
- Native Snowflake integration