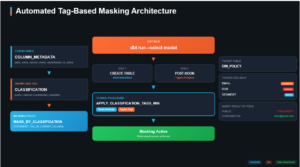
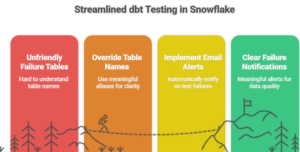
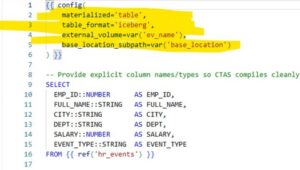
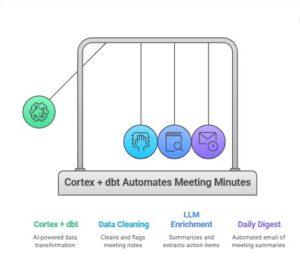
In modern data workflows, schema changes are inevitable — new fields, revised tables, and ever-evolving business logic. In this post, I’m sharing a macro-driven strategy that showcases the synergy between DBT and Snowflake, where schema evolution is not a blocker — it becomes a feature.
This approach removes the need for:
- Manual updates to your SELECT statements
- Reordering columns manually in the target table
- Rigid transformation logic tied to static schemas
Instead, we dynamically:
- Detect and align schema changes
- Ensure new columns land in the correct order
- Log schema modifications automatically
- And most importantly — we do it all without hardcoding a single column name.
Technical Implementation:
Technical Implementation:
Let’s say during the initial run, we built a DBT model based on a simple business requirement — to flag expense claims that exceed allowed policy limits.

This model created a new table: STG_EXPENSE_VIOLATIONS.
So far, so good.
Problem: Schema Drift and Model Fragility
Imagine your source table EXPENSE_CLAIMS evolves — a new column like CURRENCY gets added:
ALTER TABLE EXPENSE_CLAIMS ADD COLUMN CURRENCY STRING;
Run dbt model again and get the error:
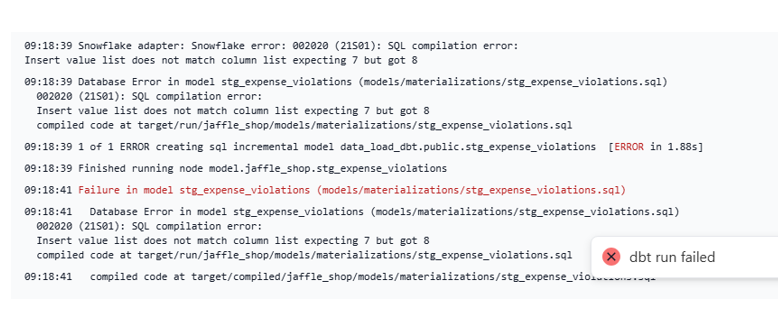
Solution: Add on_schema_change=’sync_all_columns’
{{ config(
materialized='incremental',
unique_key='CLAIM_ID',
database='data_load_dbt',
schema='public',
on_schema_change='sync_all_columns',
incremental_strategy='insert_overwrite'
) }}
DBT tells Snowflake:
“If my model schema changes, automatically align it with the latest structure (add/remove columns in the target table).”
When Things Broke: The Need for Prefixed Selection and Column Ordering
After enabling on_schema_change=’sync_all_columns’, we expected new columns from the source (like CURRENCY) to be automatically added to the target table — and they were. But then we hit a compilation error.

This approach led to ambiguous column errors. Why? Because both expense_claims (r) and policy_limits (p) had a CATEGORY column.
The Fix
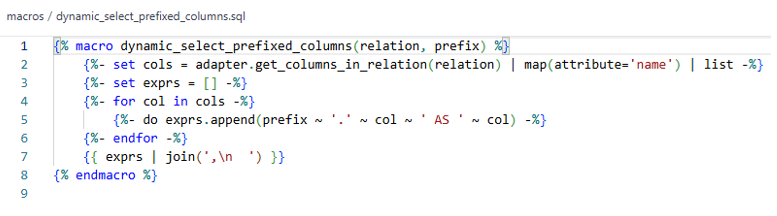
The Fix: Using dynamic_select_prefixed_columns
To resolve the ambiguity, we introduced the macro dynamic_select_prefixed_columns. This macro:
- Dynamically selects all columns from the source relation
- Prefixes each column with its table alias (like r.CLAIM_ID AS CLAIM_ID)
- Prevents column conflicts in joins
- Adapts automatically when new columns are added
Once we resolved ambiguity, the next challenge was column ordering.
When new columns are synced into the target table (via sync_all_columns), they are typically added at the end of the table. The error occurred because I was using r.* (or a macro that expands to all columns from the source), and the newly added column (e.g., CURRENCY) changed the position of columns in the compiled SQL.

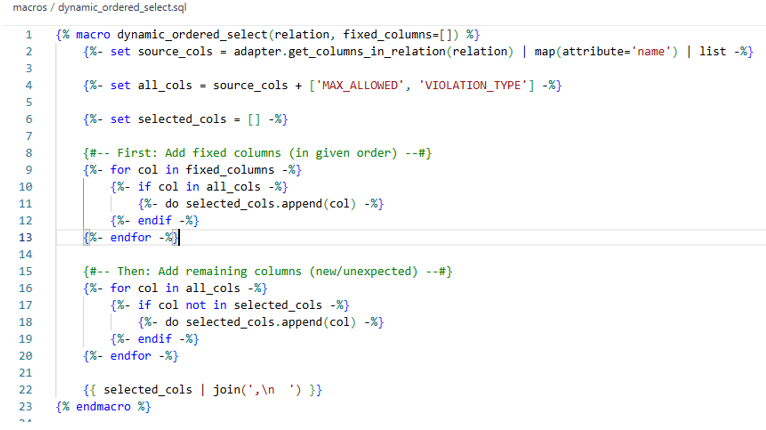
That’s where macro dynamic_ordered_select shines.
What It Does:
- Takes a list of business-critical columns (like CLAIM_ID, AMOUNT, VIOLATION_TYPE)
- Selects those first, in the order you define
- Then appends any remaining columns, including newly added ones
Produces a clean, complete, and stable SELECT statement.
Post-Hook Procedure:
At the end of each model run, we trigger a stored procedure CHECK_SCHEMA_CHANGE_JS using DBT’s post_hook. This procedure performs a schema audit by:
- Querying Snowflake’s metadata (INFORMATION_SCHEMA.COLUMNS)
- Comparing current table columns with previously known columns stored in an audit table
- Logging any newly added columns to a central SCHEMA_CHANGE_LOG
- Updating the snapshot of known columns in KNOWN_COLUMNS
Final DBT Model Putting It All Together:
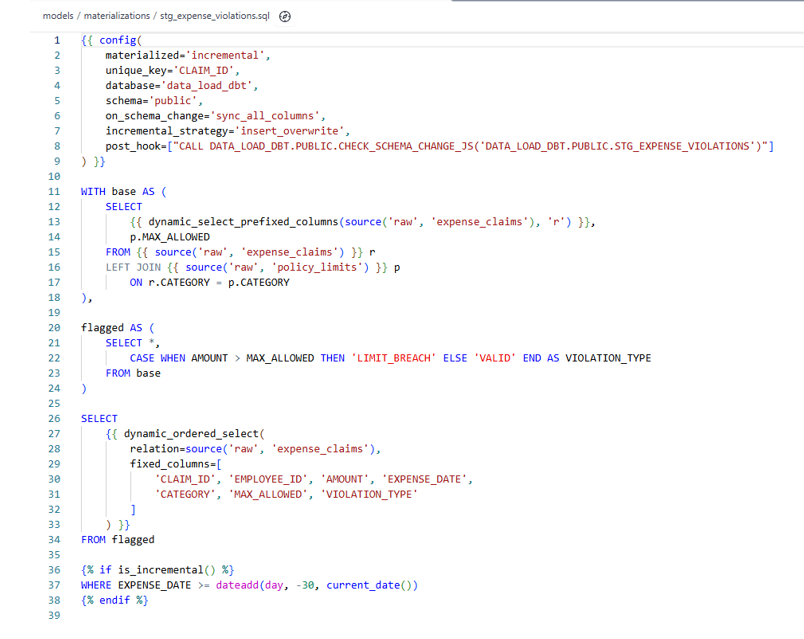
Model Summarize:
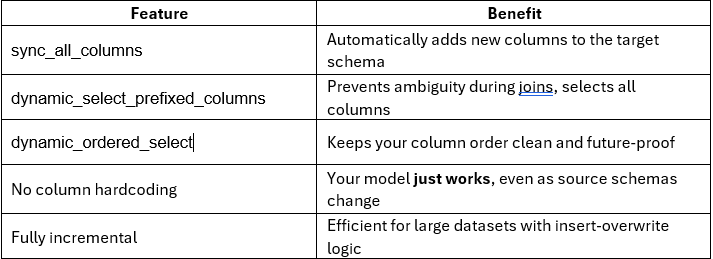
Conclusion:
By combining DBT’s schema sync capability with smart macros, we’ve achieved a robust pattern for dynamic data modeling. This approach saves countless hours of manual intervention, reduces breakage risk, and empowers teams to focus on business logic rather than schema maintenance