
In continuation of previous post, below is the Structure of Parquet file used to implement our requirement and table partition is done on the METADATA$FILENAME pseudo column.
Parquet is an open source file format available to any project in the Big data ecosystem. Apache Parquet design for efficient as well as performant flat columnar storage format of data compared to row based files like CSV or TSV files. Please note, Parquet is optimized to work with complex data in bulk and features different ways for efficient data compression and encoding types. This approach is best especially for those queries that need to read certain columns from a large table. Parquet can only read the needed columns therefore greatly minimizing the IO.
- Parquet File Structure:
Column details:
column# column_name Datatype
=====================================================
1 registration_dttm timestamp
2 id int
3 first_name string
4 last_name string
5 email string
6 gender string
7 ip_address string
8 cc string
9 country string
10 birthdate string
11 salary double
12 title string
13 comments string
AWS File folder structure :
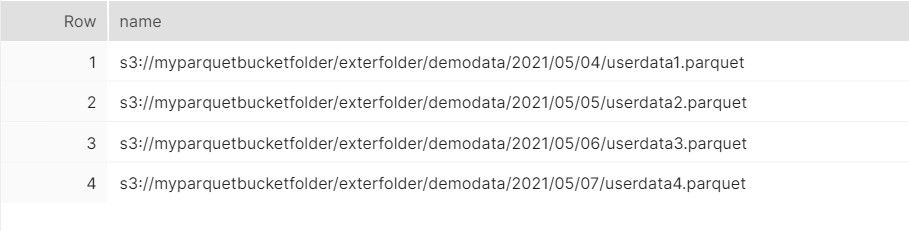
Technical Steps:
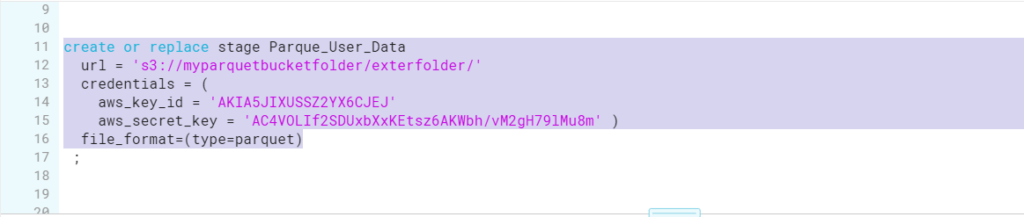
- Firstly, Create the Stage pointing to the AWS S3 location where File would be coming on daily basis. Please check the URL for the S3 location, it is not pointing to the complete path.
- Copy the file to the respective folders, emulating the behavior that we are getting Demographic file on daily basis and file gets copies to the Date folder:
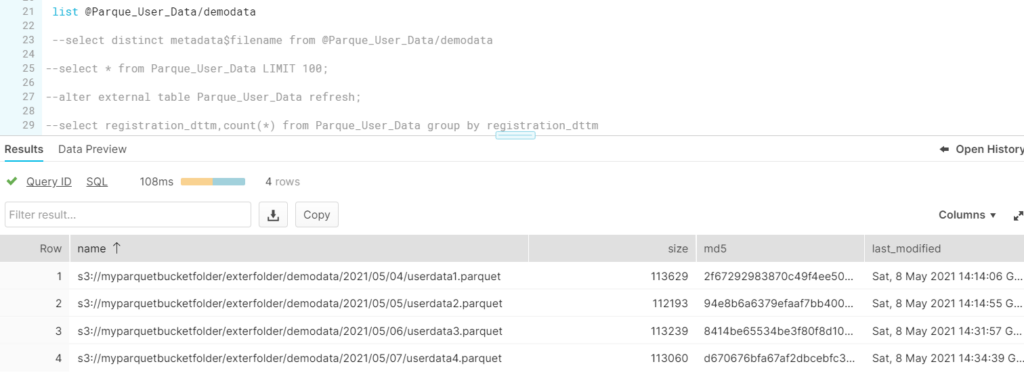
List the new stage and you will see the structure as follows:
- Create the Partition on YYYY/MM/DD format from the metadata$filename.
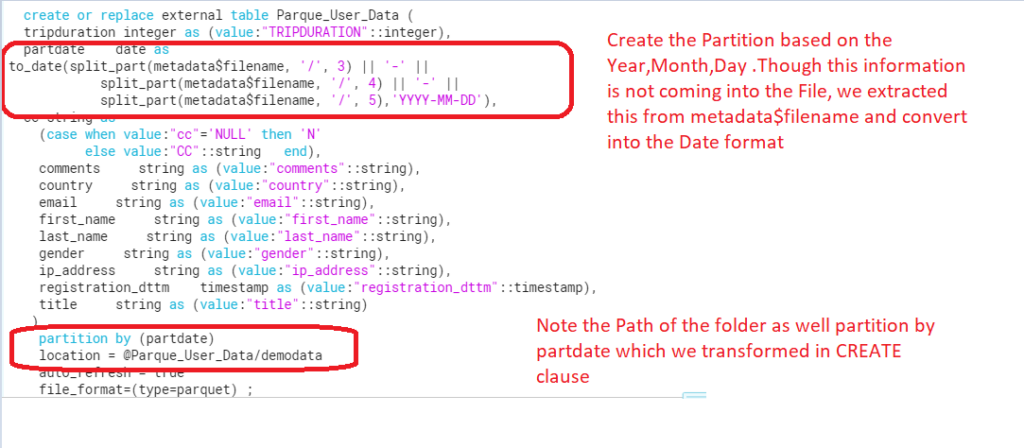
- However, before Creating the External table ,if you want to see your desired partition date format, Use the below sql.
select distinct metadata$filename,
to_date(split_part(metadata$filename, '/', 3) || '-' ||
split_part(metadata$filename, '/', 4) || '-' ||
split_part(metadata$filename, '/', 5),'YYYY-MM-DD')
from
@Parque_User_Data/demodata LIMIT 100; - Finally, Once the External table available ,query the table in same way we do on regular tables.
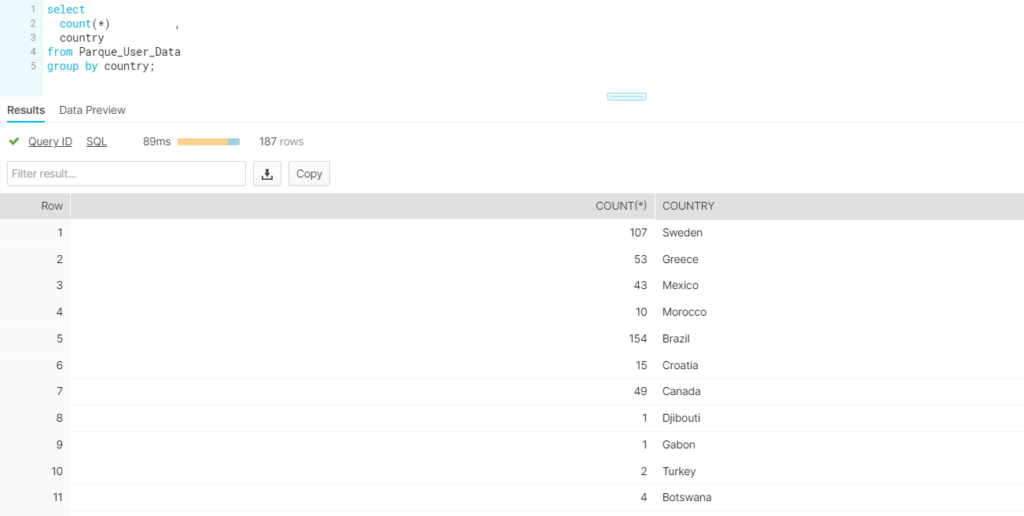
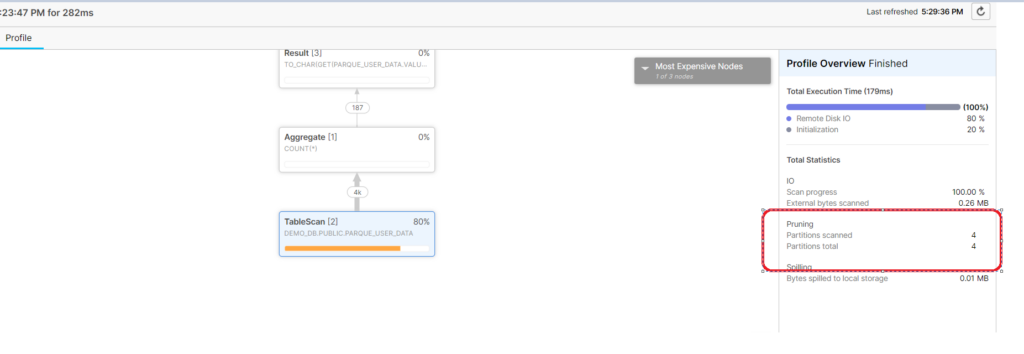
- Execute the sql including the partition in filter clause and verify the count:
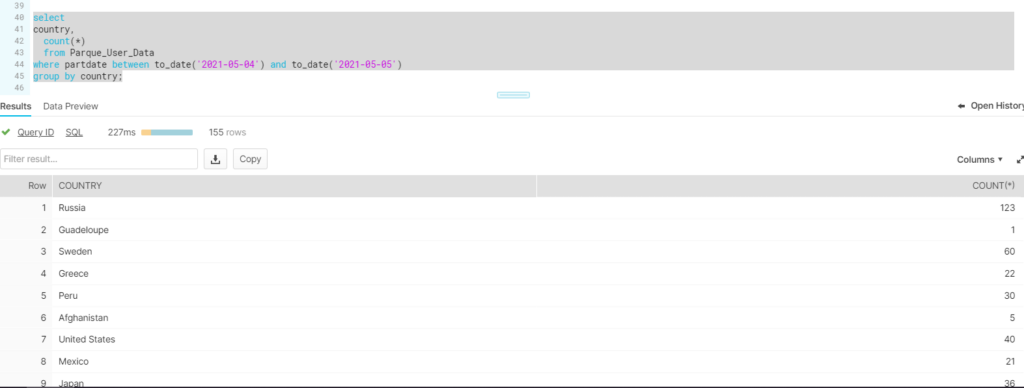
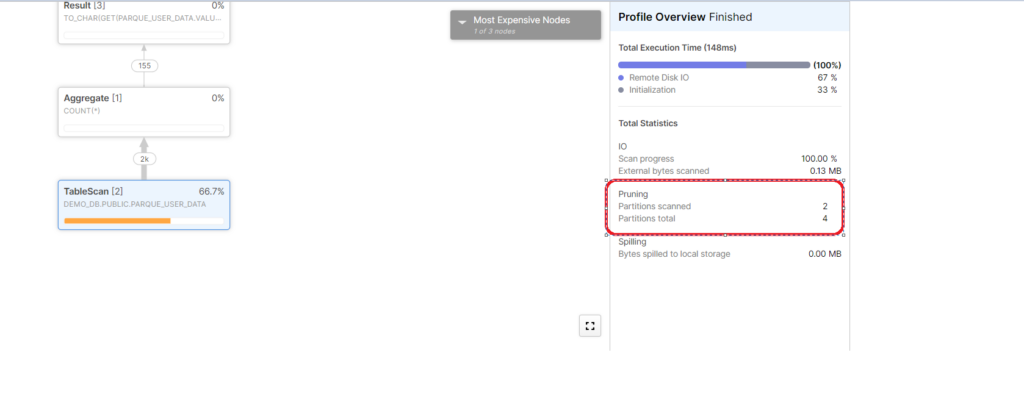
Note: Now ,Uploading the new file to the s3 location will not automatically refresh the contents inside the External table as notifications for an S3 bucket has not been configured . To make the file contents available you need to refresh explicitly.
alter external table Parque_User_Data refresh;







