Dynamic Tables + IMMUTABLE: If you’ve built any “AI-like” enrichment in a data pipeline—sentiment scoring, classification, extraction, or even LLM calls—you’ve probably seen this pattern:
New data arrives every few minutes, but your transformation keeps reprocessing old history again and again.That’s not just wasteful—it directly impacts refresh latency and compute cost.
Imagine an e-commerce review platform:
- Reviews arrive continuously
- Analytics teams want sentiment monitoring in near real-time:
- “How many negative reviews today?”
- “Which products are trending downward?”
- The scoring step is expensive (ML model, Python logic, or LLM inference)
Over time, the table grows:
- 50K new reviews this month
- 500K historical reviews from previous months
Now the critical question becomes:
Why should I keep re-scoring the 500K historical reviews that never change?
The Solution: Dynamic Tables + IMMUTABLE WHERE + Python UDTF
In this blog, I’ll walk you through a real-world demo using:
- Dynamic Tables – to keep downstream tables automatically fresh
- Python UDTF – to simulate expensive ML/AI scoring inside Snowflake
- IMMUTABLE WHERE – to freeze historical rows so they never get re-scored
In this demo, sentiment scoring is implemented using a Python UDTF, and here’s why that’s significant: For demo its a substitute for:
- An ML scoring function
- A feature extraction step
- An external model call (like calling an LLM API)
When you have expensive row-by-row transformations that don’t need to be recalculated for historical data, IMMUTABLE WHERE becomes your cost-saving superpower.
Step-by-Step Demo
Source table: CUSTOMER_REVIEWS Contains ~550K rows:
- 500K historical reviews (older than Jan 10, 2026)
- 50K recent reviews (Jan 10, 2026 onwards)
Two Dynamic Tables (same output, different cost profile)
- Baseline (no immutability): REVIEWS_SCORED_BASELINE
- Re-scores all 550K reviews on refresh
- Optimized (immutability enabled): REVIEWS_SCORED_OPTIMIZED
- Re-scores only recent reviews
Technical:
Step1: Load and verify the data in base table i.e. CUSTOMER_REVIEWS
SELECT
CASE
WHEN review_date < '2026-01-10'::DATE THEN 'HISTORICAL (Will be IMMUTABLE)'
ELSE 'RECENT (Will be MUTABLE)'
END AS data_category,
COUNT(*) AS review_count,
ROUND(COUNT(*) * 100.0 / SUM(COUNT(*)) OVER(), 1) AS percentage
FROM customer_reviews
GROUP BY 1
ORDER BY 1;

Step2: Build a Python UDTF for Sentiment Analysis
This simulates an expensive ML operation—think calling an LLM API, running a classification model, or performing complex feature extraction.
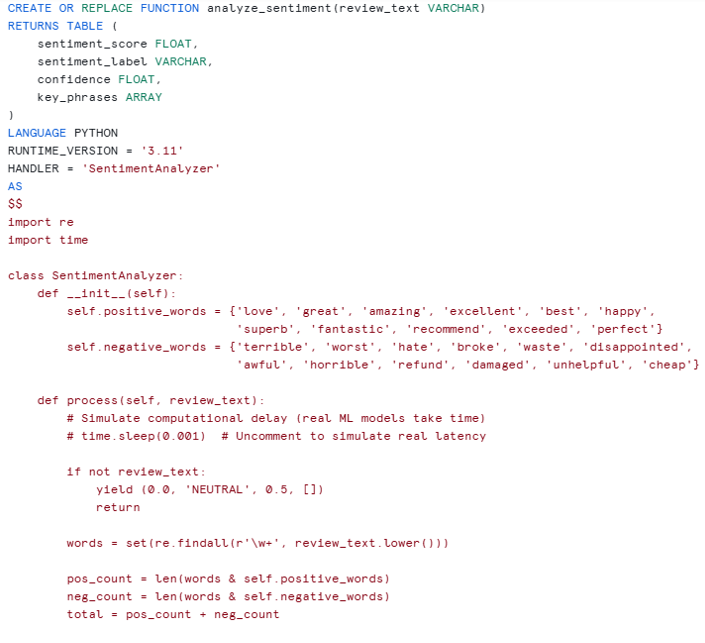

Step 3: BASELINE Dynamic Table (Without IMMUTABLE)
This is the traditional approach—re-processes all rows on every refresh.
CREATE OR REPLACE DYNAMIC TABLE reviews_scored_baseline
TARGET_LAG = '10 minutes'
WAREHOUSE = DEMO_WH
AS
SELECT
r.review_id,
r.customer_id,
r.product_id,
r.review_text,
r.rating,
r.review_date,
s.sentiment_score,
s.sentiment_label,
s.confidence,
s.key_phrases
FROM customer_reviews r,
TABLE(analyze_sentiment(r.review_text)) s;
The Problem: Every refresh processes all 550,000 rows through the Python UDTF.
Step 4: OPTIMIZED Dynamic Table (With IMMUTABLE WHERE)
Now we freeze historical reviews using the IMMUTABLE WHERE clause.
CREATE OR REPLACE DYNAMIC TABLE reviews_scored_optimized
TARGET_LAG = '10 minutes'
WAREHOUSE = DEMO_WH
IMMUTABLE WHERE (review_date < '2026-01-10'::DATE)
AS
SELECT
r.review_id,
r.customer_id,
r.product_id,
r.review_text,
r.rating,
r.review_date,
s.sentiment_score,
s.sentiment_label,
s.confidence,
s.key_phrases
FROM customer_reviews r,
TABLE(analyze_sentiment(r.review_text)) s;
The Optimization: Each refresh only processes ~50,000 active rows through the Python UDTF.
Step 5: Verify Immutability (The Visual Proof!)
Snowflake adds a hidden metadata column METADATA$IS_IMMUTABLE to track frozen rows.
SELECT
CASE WHEN METADATA$IS_IMMUTABLE
THEN ' IMMUTABLE (Frozen - Never Re-Scored)'
ELSE ' MUTABLE (Active - Re-Scored on Refresh)'
END AS status,
COUNT(*) AS row_count,
ROUND(COUNT(*) * 100.0 / SUM(COUNT(*)) OVER(), 1) AS percentage
FROM reviews_scored_optimized
GROUP BY 1;

Step 6: Simulate New Data & Measure the Impact
Let’s add 5,000 new reviews and trigger refreshes on both tables.
ALTER DYNAMIC TABLE reviews_scored_baseline REFRESH;
ALTER DYNAMIC TABLE reviews_scored_optimized REFRESH;
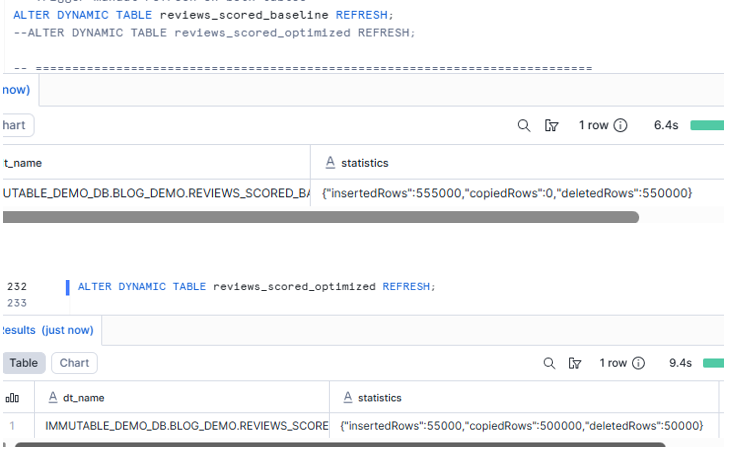
Baseline
- re-scores sentiment for everything
- reprocesses historical data again
Optimized
- re-scores only new / recent reviews
- frozen region remains untouched
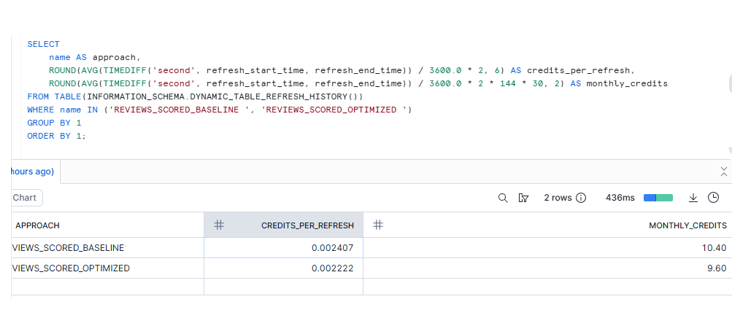
Step 7: Calculate Your Savings
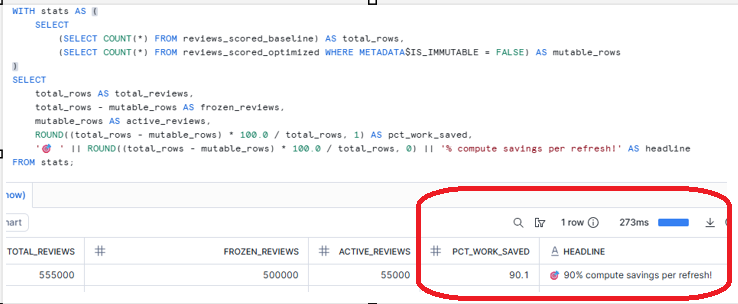
This gives you a clean conclusion line that:
We avoided reprocessing ~90% of rows on every refresh.
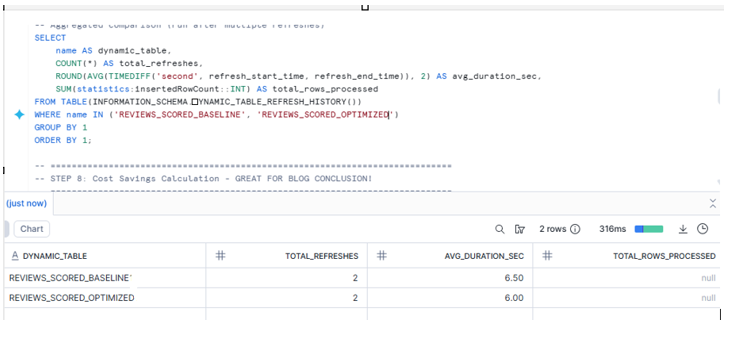
Final takeaway
If your Dynamic Table includes expensive transformations (Python UDTFs, feature extraction, ML logic) and most of your dataset is historical:
- IMMUTABLE WHERE is one of the cleanest Snowflake-native ways to reduce refresh cost
- improve refresh latency
- and keep your pipeline real-time for new data