With Snowflake’s Iceberg Tables feature, you can manage Iceberg data stored in your cloud storage—retaining all the advantages of Iceberg’s open format while benefiting from Snowflake’s powerful query engine, governance, and security. In this blog, we’ll explore two approaches for creating and loading Iceberg tables in Snowflake using dbt: a macro-driven method that offers complete control, and the new native dbt Iceberg table support that simplifies configuration.
- Traditional macro-driven approach (full control)
- New native dbt Iceberg table format support (simpler config)
Use Case
We need to store HR event data in a Snowflake-managed Iceberg table hosted in our external cloud storage (S3/Azure/GCS). We want:
- The first run to create and seed the Iceberg table.
- Implement the new native open table DBT format for Iceberg table
- All orchestration handled within dbt, no manual SQL in Snowflake.
We’ll cover:
- Architecture & prerequisites
- dbt project setup
- Macros and models to create Iceberg
- DBT Native format for Iceberg.
- Demo run & verification
Technical Implementation:
- Architecture Overview
Components:
- Snowflake: Catalog and query engine for Iceberg.
- External Volume: Points to the location in your cloud storage where Iceberg data files live.
- dbt Cloud (or Core): Orchestrates the creation and incremental loading process.
- Macros: Encapsulate reusable SQL for Iceberg operations.
- Model: Generates HR event data for use case .
- Prerequisites
Before running dbt:
- External Volume in Snowflake pointing to your bucket/prefix:
create external volume iceberg_int
storage_locations =
(
(
name = 'iceberg_bucket'
storage_provider = 'S3'
storage_base_url = 's3://srcbucketsachin/'
storage_aws_role_arn = 'arn:aws:iam::913267004595:role/icebergconfigrole'
)
);
- dbt Project Structure
- Macros
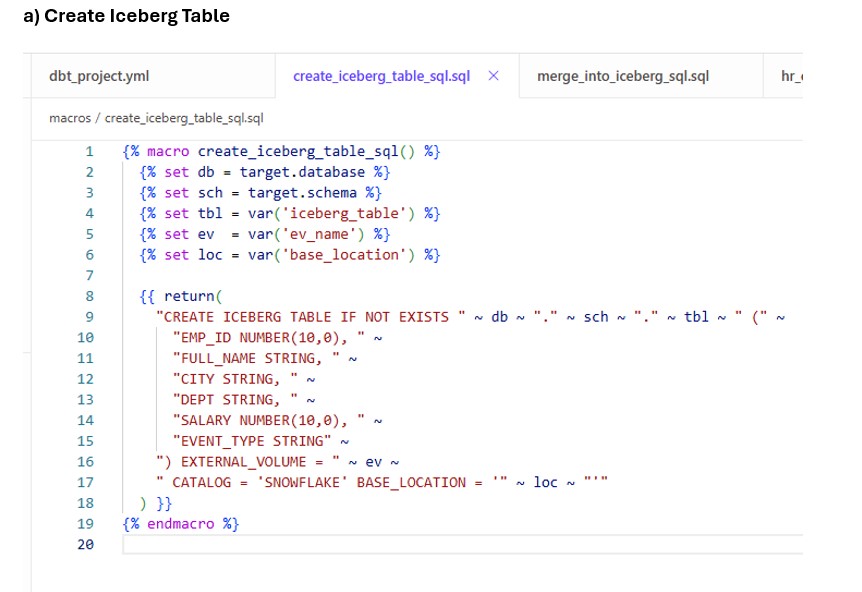
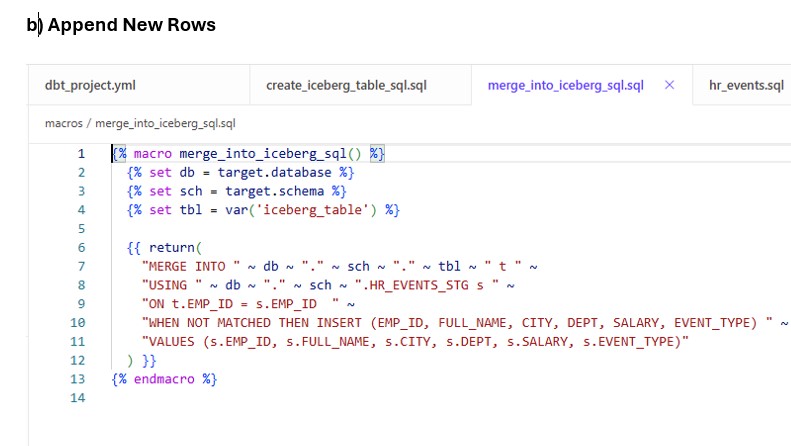
- Staging Model : models/iceberg_hr_demo/staging/hr_events.sql
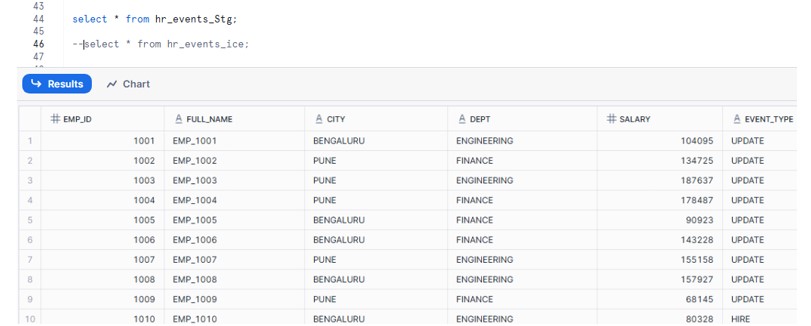
This model generates 500 new employees for our use case and creates the Iceberg table using macros defined earlier.
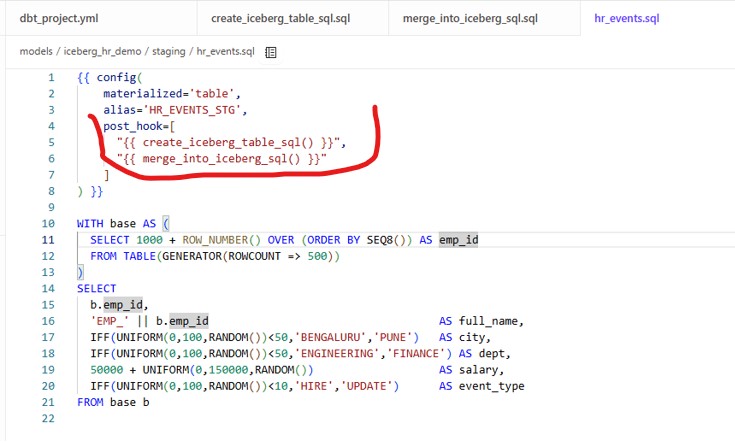
Run the model:
dbt run --select iceberg_hr_demo.staging.hr_events
Location in AWS:
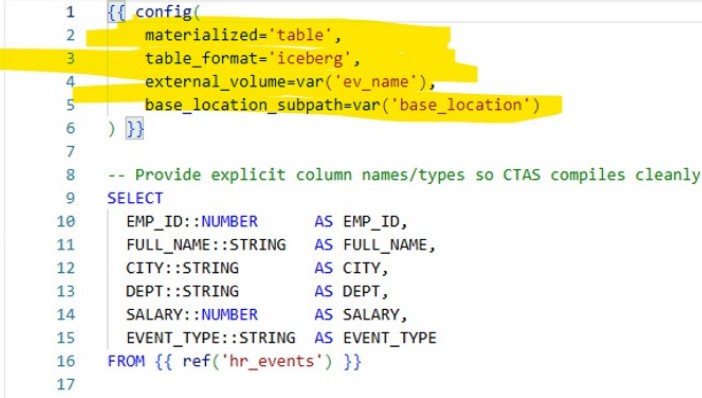
Approach 2 – Native dbt Iceberg Support (New Way)
Snowflake’s dbt adapter now supports Iceberg as a first-class table format. You can skip custom macros entirely.
models/iceberg_hr_demo/staging/hr_events_ice_native.sql
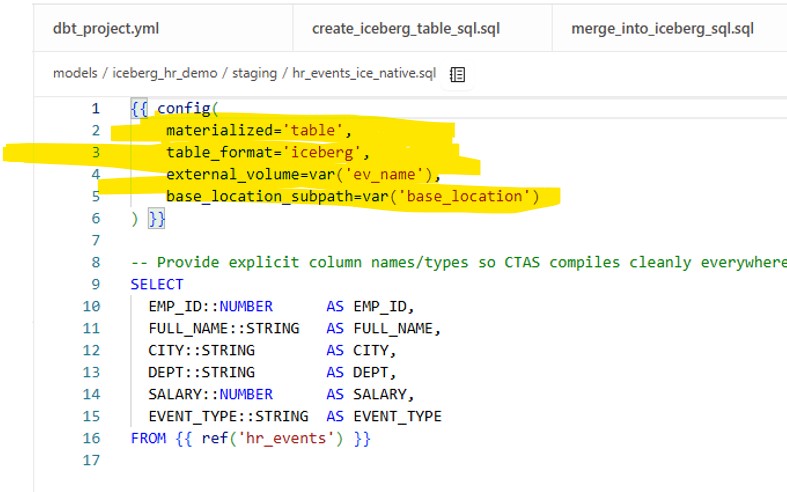
This automatically:
- Creates the Iceberg table with the right schema.
- Loads data from the staging model.
- Requires no custom SQL macros.
In this blog, we explored two ways to create and load Iceberg tables in Snowflake using dbt.
First, we implemented a macro-driven approach that gives complete control over the table creation process and incremental MERGE logic, making it ideal for scenarios where business rules determine how and when data is loaded.
Then, we showcased the new native dbt Iceberg configuration, which allows you to define Iceberg tables with just a few lines of config—making setup faster and easier for straightforward pipelines.