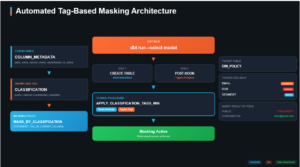
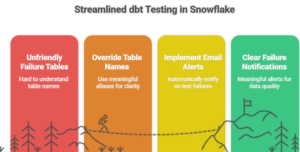
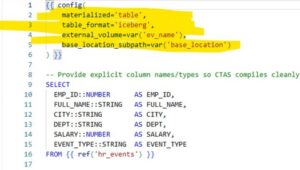
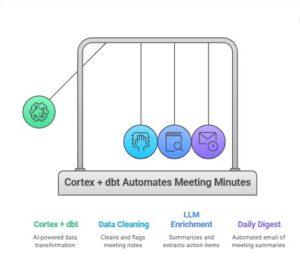
In this blog, “SQL & Python Unite: dbt Feature Pipeline,” I’ll walk you through a real-world use case where I combined the power of SQL, Python (Snowpark), and dbt to build a production-ready feature pipeline. The goal?
To track user session activity over the last 7 days, count the number of distinct active days per user, and store it incrementally as new data flows in.
But what makes this pipeline special is that we intentionally used both dbt-SQL and Snowpark-Python in the same workflow . We didn’t do this just out of technical necessity. Our goal was to show the community how SQL and Python can work together in dbt. It also highlights how Snowpark pushes the limits of traditional dbt workflows. Python makes rolling window calculations, grouping, and ordering easier to read and maintain. This becomes especially helpful as business logic grows more complex over time
Pipeline Overview
Pipeline Overview
Our feature pipeline consists of 3 models:
- Raw Cleanup (SQL): Clean and deduplicate user sessions
- Feature Engineering (Python – Snowpark): Count active session days in a 7-day window
- Final Table (SQL – Incremental): Store the results with audit tracking and incremental loading
This hybrid approach helped us demonstrate how dbt can seamlessly integrate SQL + Python for robust data pipelines.

DBT Source Table
- stg_user_sessions.sql – Clean & Deduplicate Sessions (SQL)
We use ROW_NUMBER() to deduplicate sessions by session_id, keeping only the latest update using last_updated. This ensures we don’t double-count sessions or use outdated rows.
{{ config(
materialized='table',
database='demo_db',
schema='public'
) }}
WITH ranked AS (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY session_id ORDER BY last_updated DESC) AS rn
FROM demo_db.public.RAW_USER_SESSIONS
)
SELECT
session_id,
user_id,
session_date,
session_duration,
last_updated
FROM ranked
WHERE rn = 1
AND session_duration > 0

2. fct_7d_active_sessions.py – Feature Calculation in Snowpark (Python)
Here’s where we calculate active days per user in a 7-day rolling window, using Snowpark’s Window and count() functions.
from snowflake.snowpark.functions import col, dateadd, current_date, lit, count
from snowflake.snowpark.window import Window
def model(dbt, session):
df = dbt.ref("stg_user_sessions")
df_recent = df.filter(
col("session_date") >= dateadd("day", lit(-7), lit("2025-07-06").cast("date"))
)
df_distinct_days = df_recent.select("user_id", "session_date").distinct()
w = Window.partition_by("user_id") \
.order_by("session_date") \
.range_between(-6, 0)
df_active = df_distinct_days.with_column(
"active_days_7d",
count("*").over(w)
)
return df_active
This model executes inside Snowflake, leveraging its compute layer and avoiding data movement.

3.user_active_summary.sql – Final Incremental Table (SQL)
This final model materializes the calculated feature into an incremental table.
It only appends new rows (based on session_date) while avoiding re-processing older data. We also log every run to an audit table via a post_hook.


Incremental Inserts & Latest Data Handling
What’s important to understand here is that new data may include sessions that haven’t been seen before, even if they belong to users we’ve already processed.
INSERT INTO demo_db.public.RAW_USER_SESSIONS VALUES
(‘S8′,’U1′,’2025-07-07’, 45, ‘2025-07-07 12:00:00’);
This record represents a new session (S8) for user U1, with a new session date (2025-07-07). Even though U1 is already in our table, this is incremental data and needs to be picked up by the pipeline.
That’s why our incremental filters are based on:
- session_date ≥ CURRENT_DATE – 7 → to catch recent activity
- session_date > max existing session_date → to ensure only new rows get appended

This project demonstrates how SQL and Python can work seamlessly together in dbt using Snowpark. By combining the strengths of both, we built a clean, scalable feature pipeline with incremental logic and real-time updates