
Json Data Update: Consider the scenario where you have already Ingested JSON file into the Snowflake table. On the daily or weekly basis, we are expecting the complete JSON file at S3 location and as per the requirement this file needs to be appended/loaded into the Snowflake.
Please note there is no Delta file or records from the source system. In fact, system is pushing the complete JSON file and instead of consuming the complete file at Snowflake we should follow the UPSERT approach. Consuming the Complete file may cause the duplicity of records as Snowflake does not enforce the primary key constraint and it is the high chances that File contains the same records which we have consumed in previous run.
To identify the delta records from source JSON file and the flattened data in the target table, we are following the below approach:
Comparison of All Columns:
Comparison of All Columns:
As our JSON data doesn’t include any key values that are natural primary key candidates, we are comparing all repeating JSON keys in the source table with the corresponding column values in the target table.
By this UPSERT approach i.e. Json Data update, we will be able to distinguish the existing records or modified / new records. We will be comparing the all-column attributes from the source table vs Target table and if we see any mismatch in any attribute it would be treated as new record and will be inserted into the target table.
Let us follow the below steps to achieve the same.
- Create the Storage Integration, File Format and Stage.
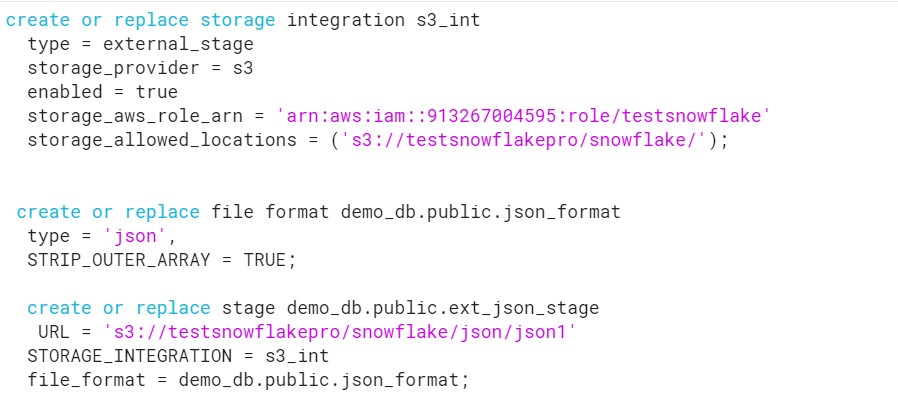
- Copy the File to S3 location:
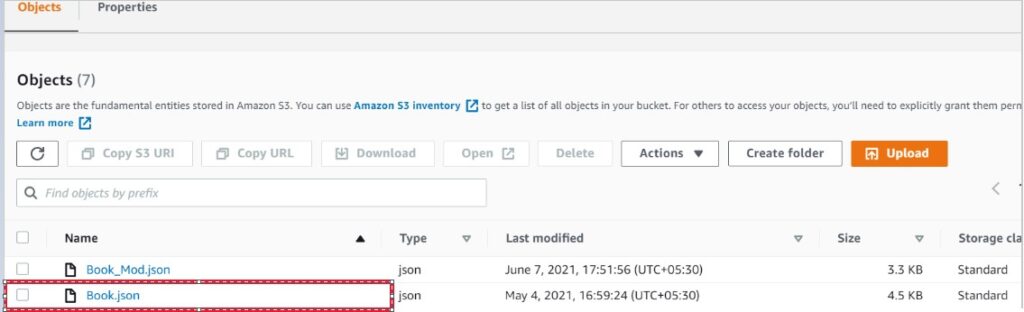
- Load the File into the table.
CREATE OR REPLACE TABLE DEMO_DB.PUBLIC.JSON_TABLE (
JSON_DATA VARIANT
);
COPY INTO DEMO_DB.PUBLIC.JSON_TABLE
FROM @DEMO_DB.public.ext_json_stage/Book.json
;
- Create the target table and store the data in FLATTENED form.
create or replace table FINAL_TABLE AS
select json_data:timestamp AS timestamp ,
book.value:symbol::string AS SYMBOL,
book.value:id::string AS BOOKID,
book.value:side::string AS SIDE,
book.value:size::string AS SIZE,
book.value:price::string AS PRICE
from JSON_TABLE,
LATERAL FLATTEN (json_data:book) as book
- Query the Final table to get the output.
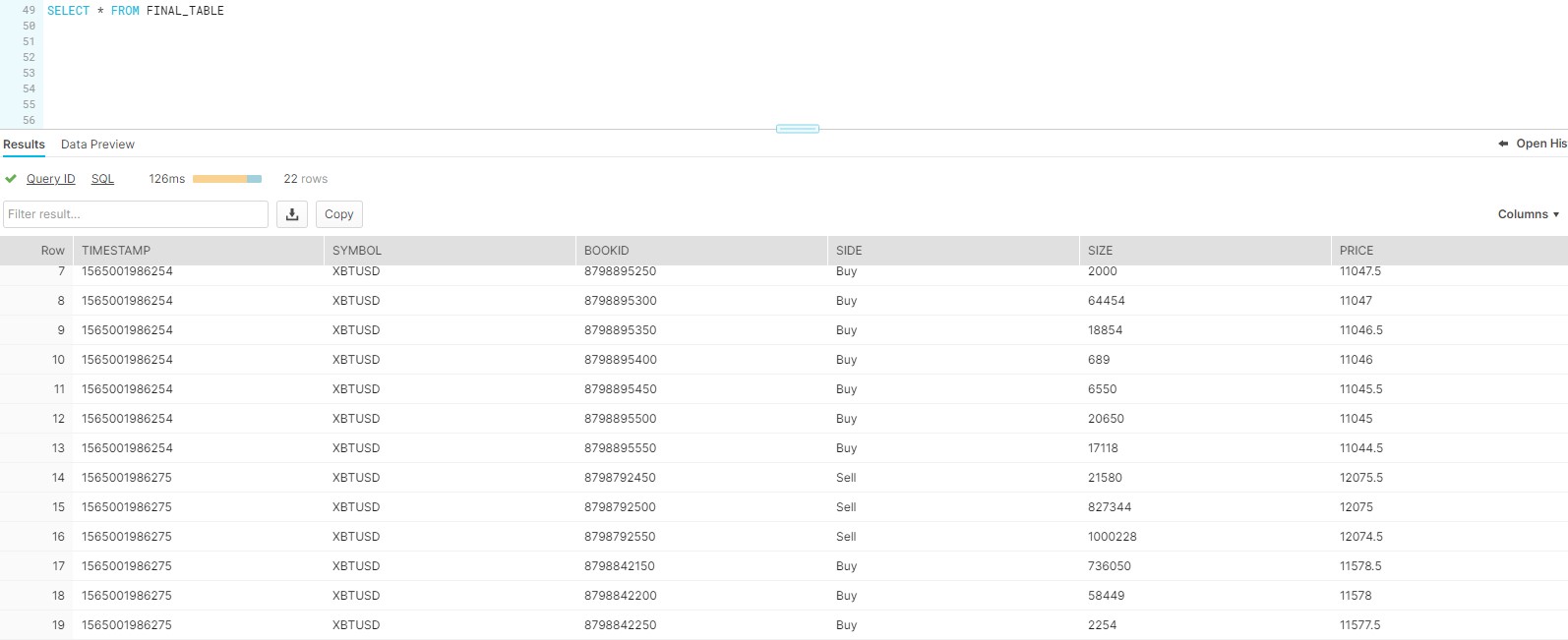
-
- For this requirement, we have modified our JSON file which includes 3 new records and 2 modified records along with existing records with no change.
- So at the time of ingesting this new JSON file into FINAL table, only 5 rows would be inserted instead of complete file.
- Copy the Modified file to the S3 location, Please refer above S3 file screenshot (Book_Mod.json).
- Truncate the source table i.e. JSON_TABLE, we can schedule it via TASK to remove the manual intervention.
- Load the file into Source table.
- For this requirement, we have modified our JSON file which includes 3 new records and 2 modified records along with existing records with no change.
COPY INTO DEMO_DB.PUBLIC.JSON_TABLE
FROM @DEMO_DB.public.ext_json_stage/Book_Mod.json
- Write the query to find out the New or Modified records.
select json_data:timestamp AS timestamp ,
book.value:symbol::string AS SYMBOL,
book.value:id::string AS BOOKID,
book.value:side::string AS SIDE,
book.value:size::string AS SIZE,
book.value:price::string AS PRICE
from JSON_TABLE,
LATERAL FLATTEN (json_data:book) as book
where not exists
(select 'x'
from FINAL_TABLE
where FINAL_TABLE.timestamp = json_data:timestamp
and FINAL_TABLE.symbol = book.VALUE:symbol
and FINAL_TABLE.BOOKID = book.VALUE:id
and FINAL_TABLE.side = book.VALUE:side
and FINAL_TABLE.size = book.VALUE:size
and FINAL_TABLE.price = book.VALUE:price
);
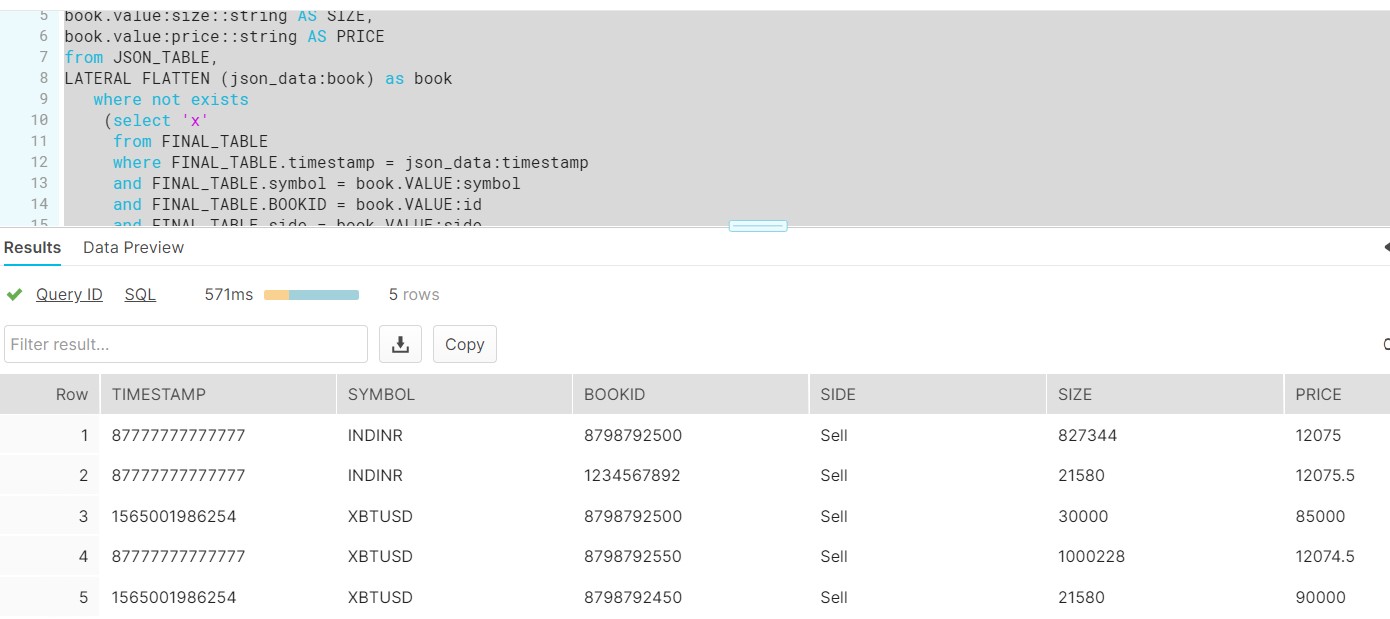
- Insert Delta records into the FINAL_TABLE.
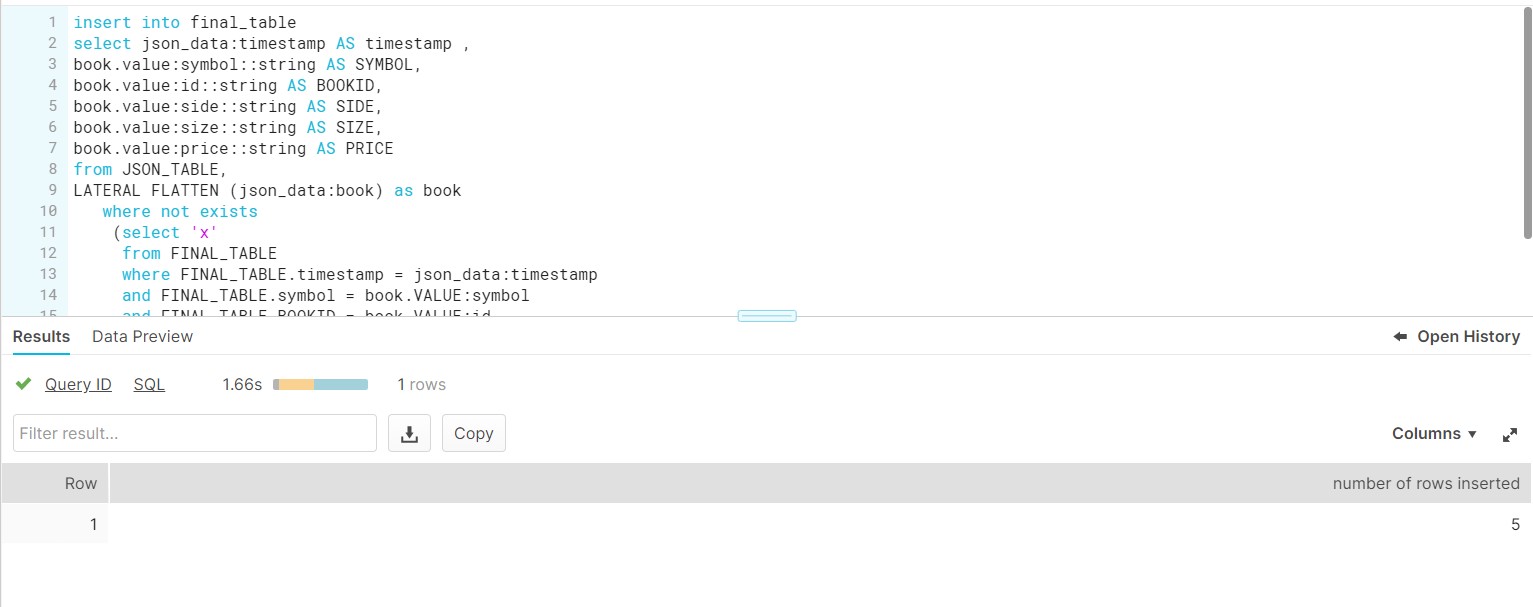
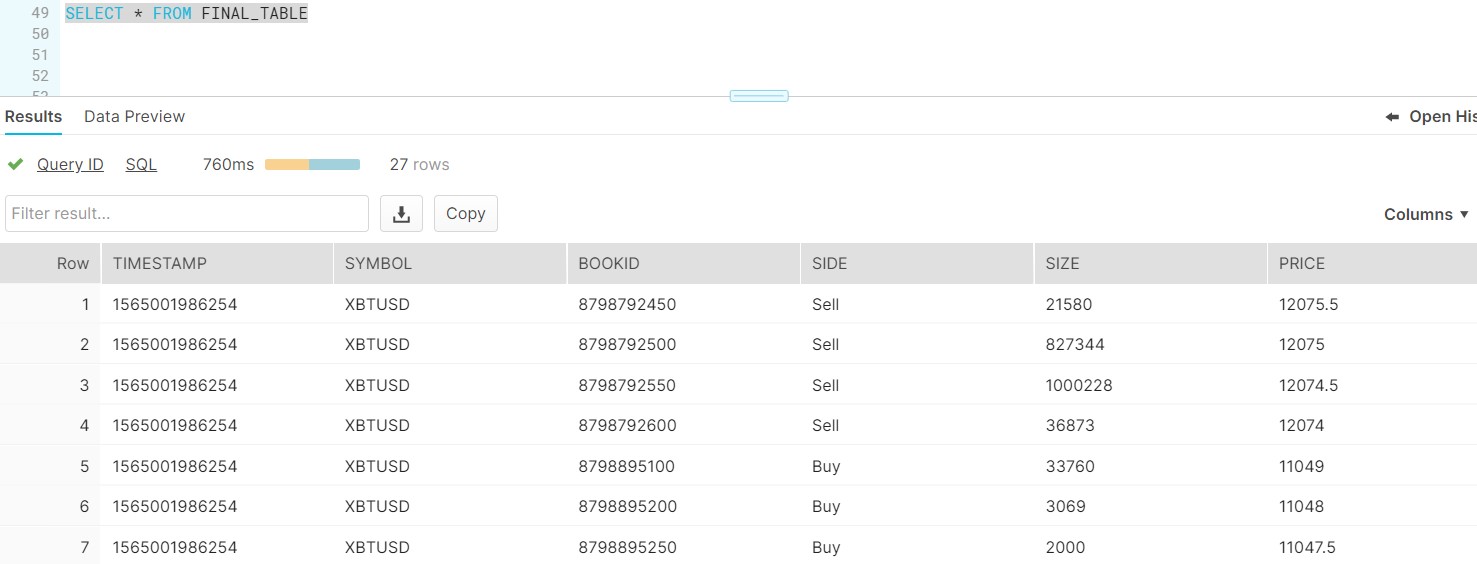
- Count the Records in FINAL_TABLE, Total count would be 27.
File:







